04 dicembre 2025
La gestione dei dati aziendali assume un ruolo sempre più centrale a mano a mano che aumentano complessità, volume e rilevanza competitiva delle informazioni. Proprio per questo, la presenza di errori o anomalie può generare conseguenze significative: dati incompleti, di scarsa qualità, non accessibili o disponibili in ritardo non possono essere utilizzati per decisioni strategiche: il loro valore e il loro potenziale si riducono così a una frazione di quello che potrebbero essere.
La data observability nasce per rispondere a questa esigenza: estende e migliora il data management permettendo di monitorare e analizzare la qualità, lo stato e i flussi di dati, individuando tempestivamente problemi e garantendo una supervisione costante lungo l’intera filiera informativa, indispensabile per valorizzare un asset diventato critico per qualsiasi organizzazione.
La crescita del mercato globale dei data observability software
|
Crescita |
1,5 miliardi di $ Il valore stimato del mercato nel 2025 |
3,6 miliardi di $ il valore del mercato previsto nel 2035 |
8,7% il CAGR previsto dal 2025 al 2035 |
|
Driver |
Crescente esigenza di qualità dei dati e monitoraggio continuo delle pipeline |
Adozione di infrastrutture dati cloud-based e piattaforme di analisi, che richiedono osservabilità avanzata |
Maggiore attenzione a governance e affidabilità dei dati nelle diverse operazioni aziendali, nei workflow di machine learning e nelle applicazioni di business intelligence |
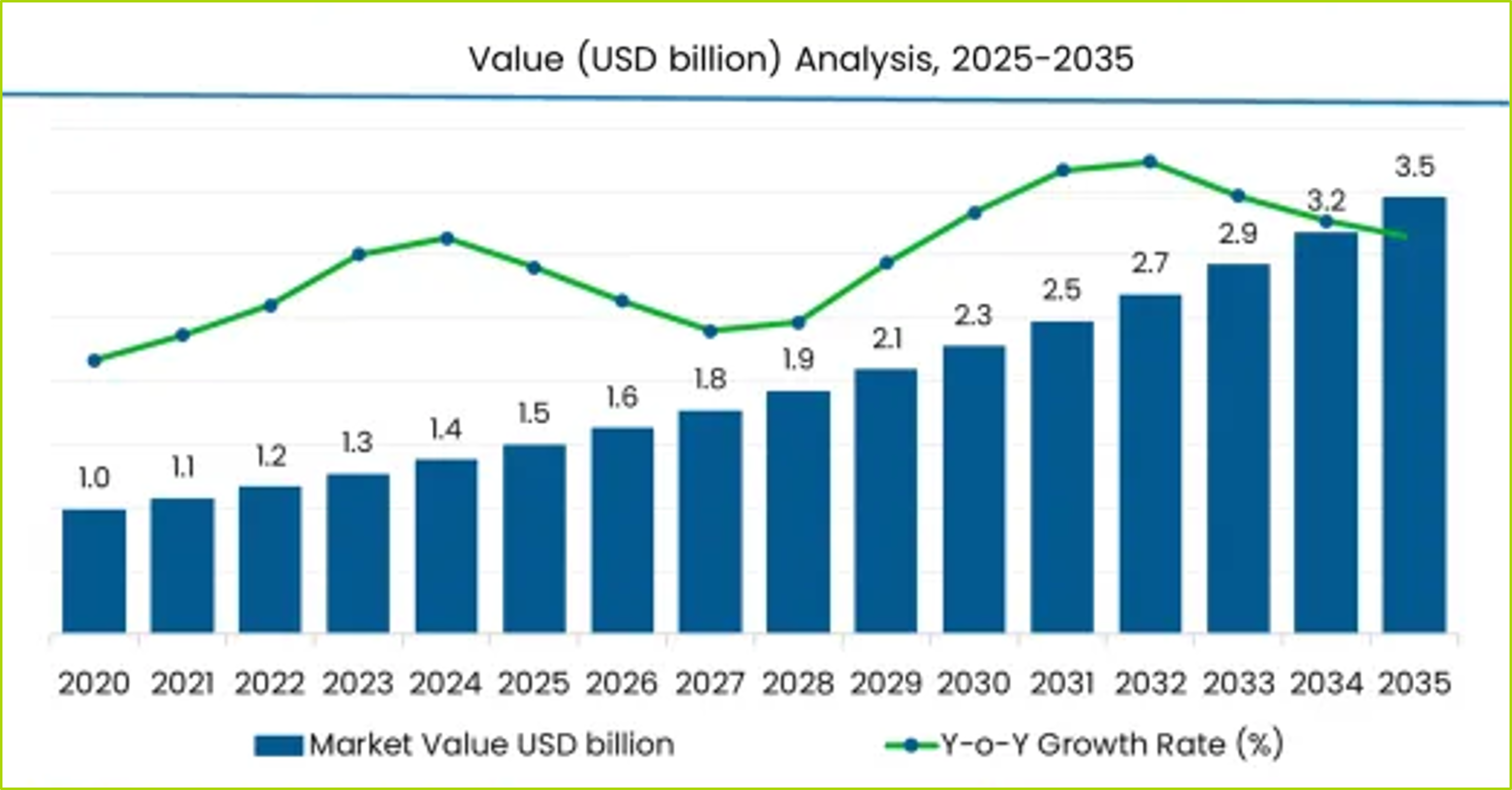
Fonte: Future Market Insights.
Come funziona la data observability
Abbiamo accennato a come la data observability sia strettamente connessa alla data governance. La ragione principale è piuttosto semplice da intuire: un controllo puntuale e costante sui dati è possibile solo quando è chiaro dove questi si trovino, come vengono utilizzati e da quali sistemi transitano. Nella pratica, si tratta di un insieme di tecniche e discipline analitiche per comprendere e controllare al meglio le pipeline dei dati, utilizzando informazioni e telemetrie raccolte dai diversi sistemi di controllo. Per avere quindi un quadro dettagliato, insomma, che copra sia i dati di per sé sia correlazioni, dipendenze e distribuzione. L’obiettivo è sapere in ogni momento dove si trovano i dati, il loro stato di salute, ma anche chi ne sta fruendo e la loro origine. Tutti questi aspetti trovano una sintesi nei cinque pilastri fondamentali della disciplina.
I 5 pilastri della data observability
1- Freschezza: verifica che i dati siano aggiornati e che le pipeline li rinnovino con la frequenza prevista, identificando eventuali ritardi o intervalli in cui gli aggiornamenti non sono avvenuti correttamente.
2 - Distribuzione: analisi dei valori dei dati per individuare anomalie, valori nulli, deviazioni dalle attese o rappresentazioni anomale che possono indicare problemi di qualità a livello di campo.
3 - Volume: controllo della completezza dei dataset, verificando che tabelle e flussi contengano il numero corretto di righe e colonne, utile per rilevare problemi nei sistemi sorgente o nelle pipeline.
4 - Schema: monitoraggio delle modifiche alla struttura dei dati (ad esempio variazioni in colonne, tipi di dato, relazioni), poiché cambiamenti imprevisti possono causare errori, interruzioni e data downtime.
5 - Lineage: mappatura dell’origine, delle trasformazioni e del percorso dei dati attraverso sistemi e processi, fondamentale per identificare rapidamente la fonte degli errori, valutare impatti a valle e supportare la governance.

Campi di utilizzo e vantaggi della data observability
Contrariamente a quanto si potrebbe pensare, la data observability non è riservata alle sole aziende che vedono nella gestione delle informazioni la loro attività core. Oggi i dati sono un asset strategico per qualsiasi organizzazione coinvolta in processi decisionali complessi e, paradossalmente, sono proprio le realtà con una minore maturità nella cultura del dato ad aver bisogno di maggior controllo e affidabilità. Il rischio, se questo non accade, è che le aziende perdano fiducia nei propri dati e nelle informazioni che da essi possono ricavare, e che si crei un gap sempre più incolmabile fra le realtà che li sanno mettere a valore e quelle che ancora non lo fanno.
Implementare una buona data observability, insomma, significa prima di tutto migliorare la qualità del dato, fattore abilitante per almeno tre dei vantaggi chiave di una strategia data driven:
|
Ottimizzazione dei processi |
Velocità decisionale |
Maggiore affidabilità delle decisioni |
|
La trasparenza delle informazioni e la possibilità di metterle a valore permettono di osservare in modo più efficace i processi aziendali e identificare sprechi e inefficienze. |
Quando è possibile accertarsi della tempestività e validità dei dati aziendali, questi possono essere utilizzati con sicurezza all’interno di decisioni rapide e immediate. |
Quando i dati sono di buona qualità e in buona salute, supportano decisioni affidabili; al contrario, dati parziali o corrotti possono condurre a errori anche gravi sul piano strategico. |
Compliance e governance: perché la data observability è sempre più centrale
La data observability è anche un eccezionale strumento per la compliance: alcune normative ne richiedono esplicitamente l’adozione, una su tutte l’AI Act nato per la regolamentazione dell’uso dell’intelligenza artificiale sul territorio Europeo. Ma anche per quanto riguarda norme e regolamenti che non la richiedono esplicitamente come adempimento può diventare un efficace strumento probatorio per dimostrare la diligenza nella gestione dei dati in caso di incidente o indagine. Tutti le normative più diffuse, da GDPR a NIS2; infatti, richiedono a qualche titolo di garantire affidabilità, sicurezza e tracciabilità dei dati, aspetti che la data observability rende più semplici, sostenibili e dimostrabili.
L’observability nell’era dell’intelligenza artificiale
L’observability sta diventando un pilastro fondamentale per garantire ambienti cloud-native efficaci e sistemi di artificial intelligence affidabili. In particolare, le aziende riconoscono che senza una visibilità completa sulle pipeline dati, sui carichi in esecuzione e sui modelli distribuiti, non è possibile scalare progetti di AI in modo sicuro. L’integrazione dell’AI nei processi aziendali porta con sé infatti un insieme di sfide che rendono ancora più necessario un approccio maturo all’osservabilità dei dati. Le preoccupazioni più diffuse, secondo il report The State of Observability 2025, riguardano:

Queste percentuali mostrano chiaramente che l’affidabilità dei sistemi di AI dipende direttamente dalla capacità di monitorare costantemente la qualità, la freschezza, la coerenza e la tracciabilità dei dati utilizzati. Per questo motivo, anche questa indagine conferma che gli investimenti stanno aumentando:
-
70% delle aziende ha incrementato il budget dedicato all’osservabilità nell’ultimo anno,
-
75% prevede ulteriori aumenti nel prossimo anno.
La data observability diventa così il fondamento per costruire modelli più sicuri, trasparenti e governabili, permettendo alle aziende di mitigare rischi operativi, reputazionali e normativi in un’epoca in cui l’AI assume un ruolo sempre più critico per il business.
Come monitorare lo stato di salute dei dati: cinque best practices
Pur non potendo delineare soluzioni universalmente valide, possiamo identificare alcune pratiche che costituiscono un punto di partenza e soprattutto che permettono di iniziare a delineare i contorni di una buona strategia di observability dei dati.
1. Definire metriche significative e universali
Identificare e standardizzare metriche rilevanti per il data lake aziendale (in qualsiasi forma questo si presenti) permette di costruire un terreno comune e universale su cui impiantare il data management prima e la data observability poi. Alcune di queste possono essere strettamente relative ai dati veri e propri, per esempio freschezza, volume delle righe, distribuzione statistica, schema, percentuale di NULL e unicità. Altre, invece, possono essere riferite alla pipeline, per esempio latenza, errori, throughput, in modo da tracciare anche le performance dei flussi dati.
2. Unificare e armonizzare il monitoraggio di dati e pipeline
Una buona data observability deve tenere conto sia della qualità dei dati veri e propri sia delle performance del processo che li genera. Monitorare in modo olistico gli obiettivi relativi alle prestazioni della pipeline e sulla qualità dei dati permette una visione più armonizzata e una identificazione più tempestiva di inefficienze, anomalie ed errori.
3. Monitoraggio automatico e avvisi in tempo reale
Observability e monitoraggio sono da sempre due temi prossimi. Anche nel caso dei dati e della loro qualità, automatizzare il rilevamento di anomalie permette di agire in modo più efficace e tempestivo. Per costruire un sistema di alerting efficace si può ricorrere a soglie intelligenti, algoritmi di machine learning e strumenti di mitigazione automatica o semi-automatica delle anomalie.
4. Tracciamento della Lineage e root-cause analysis
Conoscere la lineage, la discendenza di un dato è importante soprattutto quando si tratta di identificare anomalie. Se la filiera del dato è coperta end-to-end è possibile risalire fino alla sorgente dei dati errati da un lato e fino al potenziale impatto per l’azienda dell’altro. Strumenti come Unified Catalog presente nelle nuove versioni di Microsoft Purview permettono, attraverso una opportuna configurazione, di avere una vista integrata di asset, domini e qualità dei dati. L’observability permette di identificare le cause con una analisi visiva e di tracciarle lungo tutta la pipeline.
5. Garantire scalabilità e miglioramento continuo
Dal momento che la quantità di dati generati dalle aziende cresce di continuo, è indispensabile che l’infrastruttura di controllo sia flessibile e scalabile. Inoltre, l’uso di piattaforme cloud o ibride permette di gestire anche sistemi di controllo sulla qualità del dato con l’opportunità di adozione rapida di soluzioni migliorative.
Data observability: dati in salute e di qualità per decisioni sempre efficaci
In un contesto in cui i dati guidano processi, innovazione e competitività, garantire visibilità e controllo sull’intero ecosistema informativo è diventato indispensabile. La data observability consente alle organizzazioni di operare su basi solide, offrendo strumenti per monitorare qualità, comportamento e coerenza dei dati lungo le diverse pipeline. Adottare un approccio strutturato all’osservabilità significa poter contare su informazioni affidabili, intervenire tempestivamente sulle anomalie e supportare decisioni più consapevoli.

Topic: Data Storage, Data Governance, Compliance